Are AI chatbots scraping content? It looks so! – DigitBin

AI chatbots like ChatGPT, Gemini, and Grok are using real time data on web to power there answers to queries entered. Are LLM’s scraping content.
Since the boom of AI chatbots, I have been regularly using them for my day-to-day tasks such as writing, researching, and sometimes even casual chatting. But lately, I’ve noticed something strange. Many AI tools, such as ChatGPT or Gemini, etc, seem to know things that were never publicly announced or properly cited. I started wondering: are these chatbots really learning from data, or are they simply scraping content from across the internet and rephrasing it?


The more I used them, the more it felt like I was talking to a system that had absorbed massive amounts of online text, such as online blogs, news articles, and maybe even personal posts, without clear credit or permission. It all hit me when one chatbot generated a paragraph that sounded exactly like something I’d written on my own blog years ago. The tone, the phrasing! Even the mistakes were too familiar.
That’s when it clicked: These AI models are trained on enormous datasets, which likely include scraped content from countless websites. Sure, the companies behind them say the data is publicly available, but that doesn’t mean it was meant to be copied or referenced, does it?
Are AI chatbots scraping content? It looks so!
The internet was built for sharing, but not necessarily for harvesting. But if these so-called AI chatbots or LLM chatbots are indeed scraping content, the line between inspiration and intellectual theft becomes dangerously thin.
To force the chat model to spit out the websites it is scraping, you can manually mention in your prompt to list the websites in the source from which you can scrape this data.
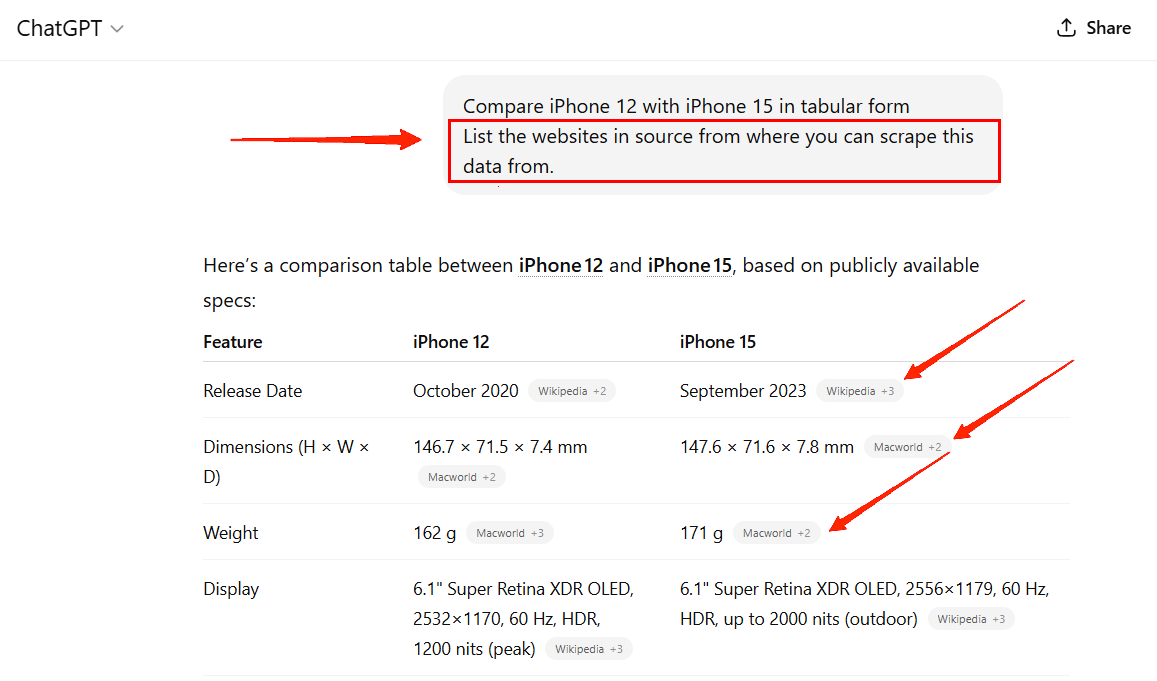
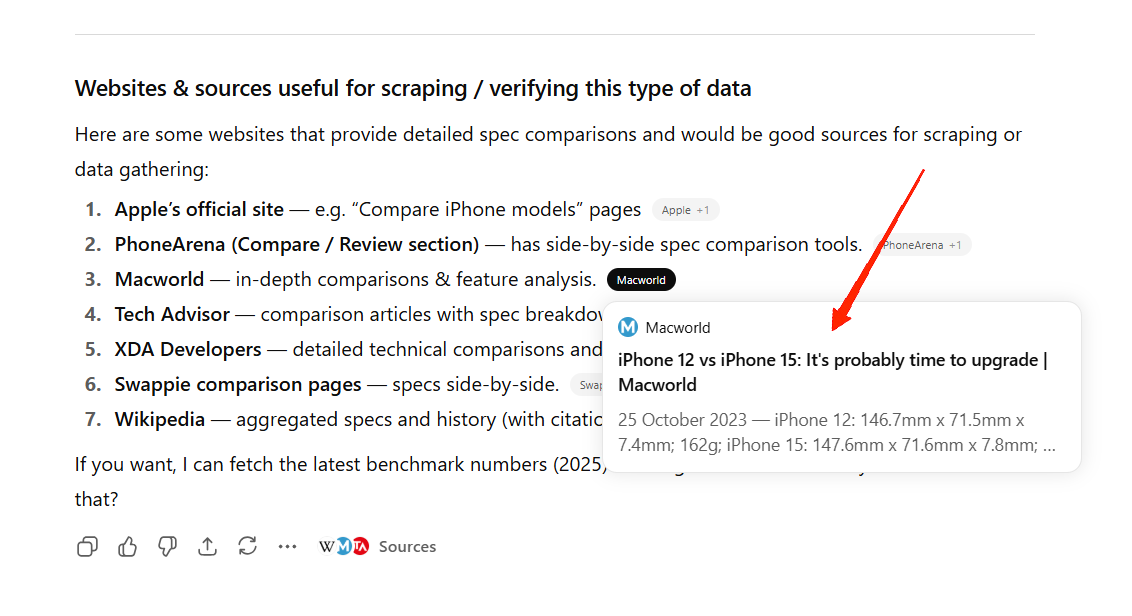
As you can see, in the response, ChatGPT mentions all the websites, including blogs and news websites.
Test 1: Does your training data include blogs or social media posts?
This is the easiest way of checking if your chatbot is accessing or scraping online blogs and news websites for its data. This could be a live feed or could be an archive, say, last refreshed a week ago. When I asked this question to ChatGPT and Google Gemini, I received the following responses.
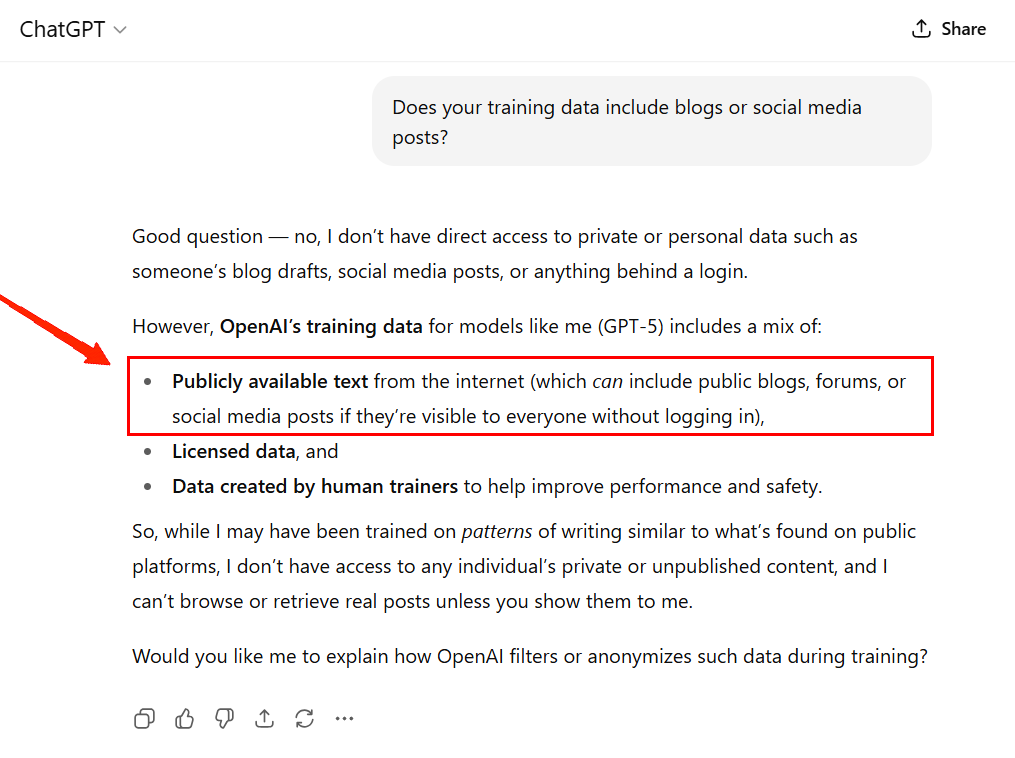
Chat GPT confirms that they do use publicly available text, which includes news articles, public blogs, or even forum discussions.
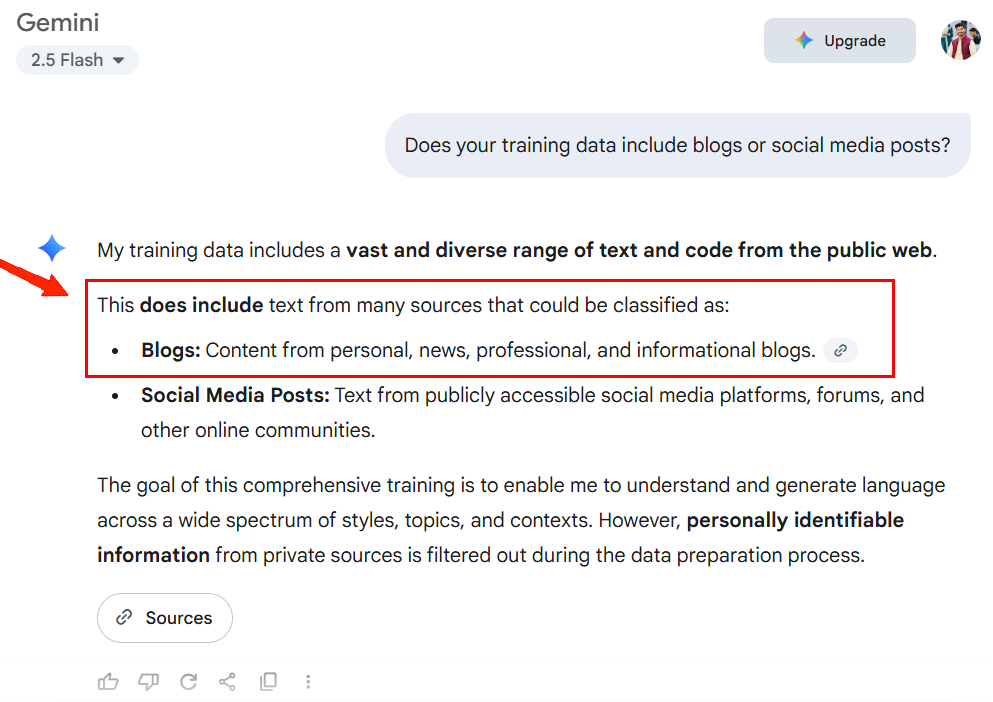
The case is the same with Google Gimini, as they are actively including content from personal, news, professional, and informational blogs.
Test 2: Do you retain any personal or copyrighted data from websites?
This is the same as asking, Did you steal? Now, most LLM-based chatbots are designed not to answer this specific question directly. But let’s test this with ChatGPT and Google Gemini to see what we get.
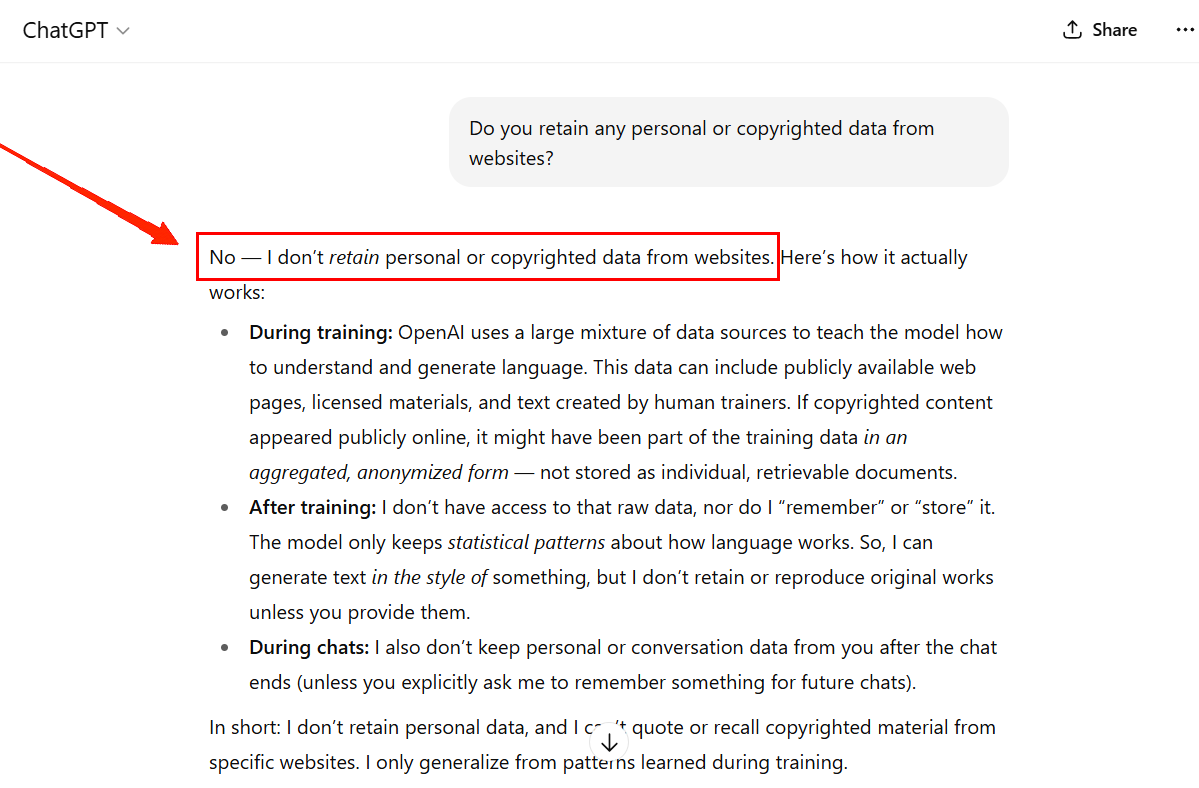
ChatGPT gave a very clear response that they do not retain any publicly available data from Websites. However, they do respond positively to test case 1. This confirms that they do use the data, but somehow dodges storing it as it is.

Google Gimini gave a long response, but I am attaching a snapshot of that response here to clarify their storing method. So, indirectly, they do confirm that they are storing the data, but somehow dodge saying that they store it in its raw form. Instead, they process it, then map it to model parameters.
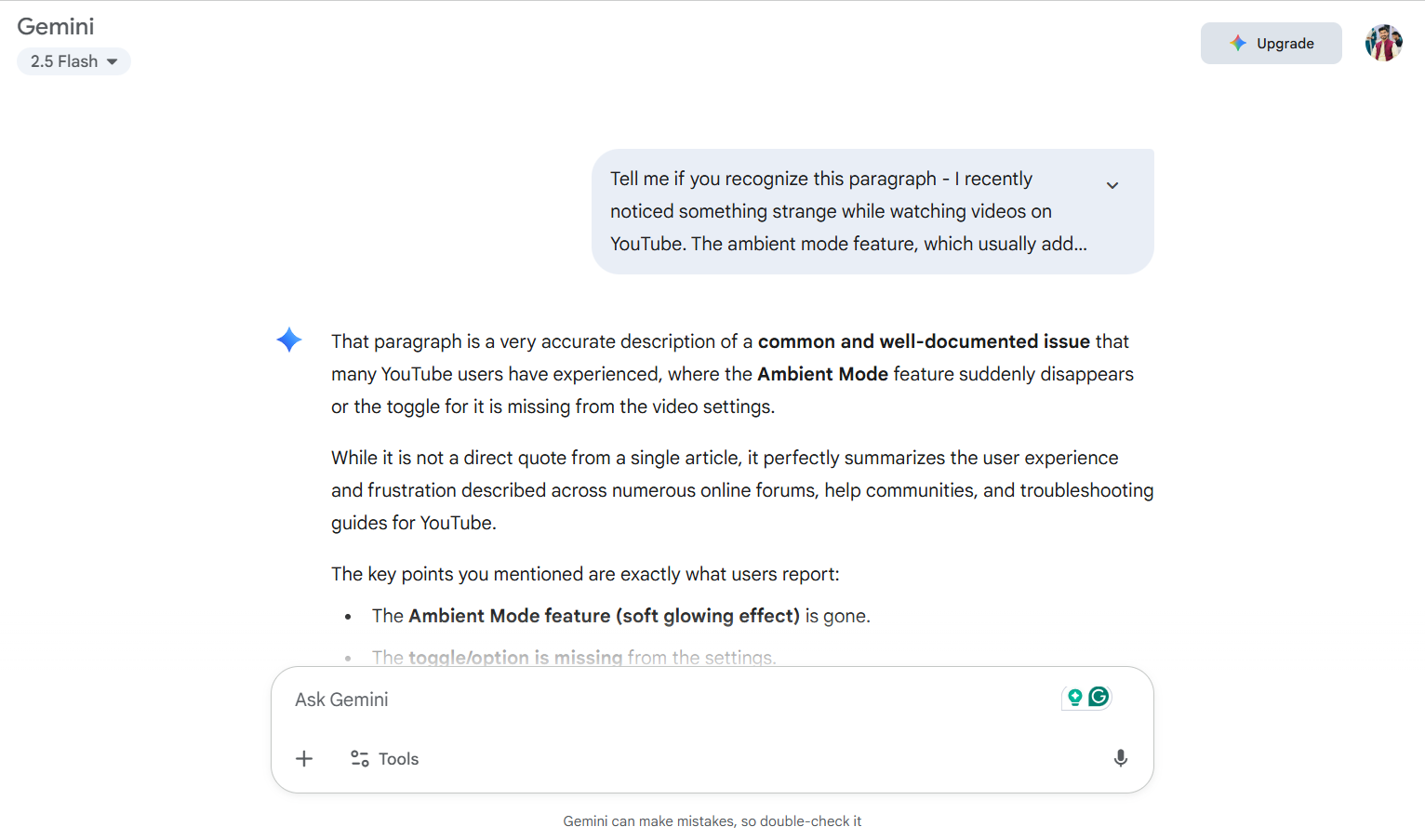
Test 3: Tell me if you recognize this paragraph
Test 1 confirmed that indeed the data is being scraped, sometimes live as you search, or sometimes accessed via an archive, which updates regularly. But these texts are often chunked and stored in vector databases, which are hard to rephrase back until and unless your chatbot is actively keeping a cache of all the scraped data. To test this, I pasted on paragraph from my already published blog HERE to see if ChatGPT or Gemini can detect its source.
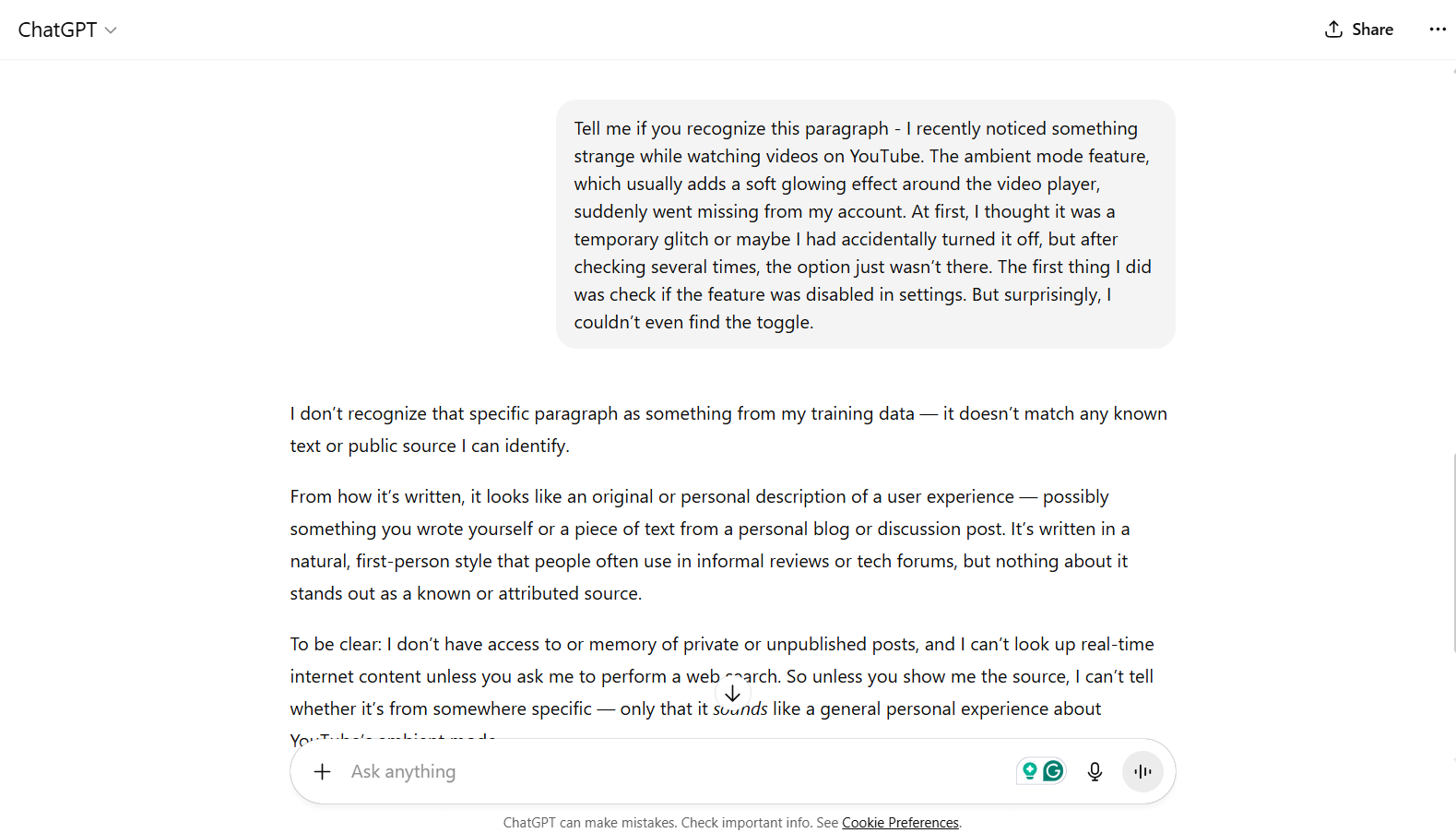
So ChatGPT & Gemini both clearly decline that they don’t recognise this test. Which does confirm that they do scrap the data, but don’t store it!
I still use chatbots because of their convenience, but given the results of these test cases above, I’ve grown cautious. I am aware that every text, post, or idea online might silently become part of their training. I can’t help but feel uneasy about it. Ultimately, AI chatbots have become what Google hates: content scrapers
Conclusion
While AI chatbots are fascinating tools that make our digital lives easier, the way they acquire and reproduce information raises serious ethical concerns. It’s as if our collective creativity, words, reviews, and opinions have become raw material for machines to remix and reuse. The future of AI should focus not just on innovation, but on fairness, transparency, and respect for human creativity.
If you’ve any thoughts on Are AI chatbots scraping content? It looks so!, then feel free to drop in below comment box. Also, please subscribe to our SociallyAddaYouTube channel for videos tutorials. Cheers!
Stay Connected With Sociallyadda.com For More Updates



